Book of Knowledge
Chapters: 1 2 3 4 5 6 7 8 9 10
List of all languages referred to in the Book of Knowledge and other sections of the website.
DOWNLOAD and print out the Book of Knowledge.
Let’s Revise! – Chapter 2
Go to the Let’s Revise section to see what you can learn from this chapter or test how much you have already learnt!
Chapter Author: Nicole Nau
Exploring Linguistic Diversity: What is different? What is common?
Exploring Linguistic Diversity: What is different? What is common?
Some people find it hard to believe that there are so many different languages in the world – 6,500 or even 7,000? Are these all real languages? Aren’t most of them just dialects? People used to the situation in Europe often think that a “real language” has a written form and a written tradition, it has been standardized and described in dictionaries and grammars, it is taught in schools, and it has official status within a state. Languages that lack these characteristics are thought to be “only dialects”, which often implies that they are incomplete and somehow inferior to languages such as English, French or Dutch. In the 19th century the European feeling of superiority was overtly expressed by labelling smaller languages of non-European cultures “primitive languages”. Today we know that there is no such thing as a primitive language. In fact, languages spoken by communities that lack western technology often have highly complicated systems and are therefore of great value to linguists.
On the other hand, when people say that something is “only a dialect” they may have in mind its similarity to another language, usually one that is better known and has a standard and/or official status. For example, they may think of Kashubian as a dialect of Polish, because these languages are similar and Polish is the dominant language in Poland. In this view, the question “language or dialect” can be answered by determining the grade of difference between two ethnolects. Unfortunately, this is not an easy task if the two ethnolects in question are genetically closely related (belonging to the same branch or subgroup of a language family, as Kashubian and Polish do; note that today Kashubian is recognized as a separate language). Most linguists today agree that the question which “lects” belong to one language and which to another cannot be decided by one or two simple criteria. Many different factors have to be taken into account, and mutual intelligibility, or grade of difference, is only one (see also Languages of the World and Endangered languages, ethnicity, identity and politics for discussion). This is one of the reasons why we are not able to give the exact number of languages spoken today. Anyhow, we are sure that there are several thousand languages in the world that differ from each other at least as much as English and German do.

Languages or dialects? (Photo: Nicole Nau)
Languages and LANGUAGE
The question “how different are the languages of the world?” can also be approached in a more principled way. It has intrigued linguists and philosophers for a long time and still causes some controversy.
Some hold that all languages are essentially the same, as they are all products of the human mind – they are manifestations of LANGUAGE, a human capacity. Children all over the world acquire their mother tongue in about the same time, which shows that from the point of view of the native speaker there are no “complicated” or “easy” languages. It has been claimed that children could not acquire a language from what they hear (the “input”) alone, but that they must possess an innate set of general linguistic rules and principles that allows them to build up the system of the language or languages of their surroundings. This innate mechanism is called Universal Grammar; it determines which structures are possible in individual languages. Some linguists claim that the aim of linguistics is to discover this abstract Universal Grammar, not to describe the different languages that are spoken in real time and space. In its most radical form, this approach may lead to the conclusion that it is enough to study one language thoroughly, but language comparison is necessary only to test one’s hypotheses. From this perspective the fact that many small languages are dying out is not a big issue, for Universal Grammar can as well be discovered from the study of English, Japanese and Arabic alone. This line of thought was very influential in linguistics, especially in the USA during the 1960s – 1980s, and its most prominent proponent was Noam Chomsky, probably among the most famous linguists of the 20th century.
On the other hand, there are linguists who hold that each language is a unique system that has to be studied and described in its own right. One cannot make generalizations or draw conclusions about language in general from the regularities found in one or two, or even a hundred, individual languages. To explore LANGUAGE, the human capacity, we need in principle all the languages that ever have been spoken by humans. As this is not possible, we cannot determine which structures are impossible in human languages, and linguists have to set themselves more humble tasks. The idea that each language has its own system that has to be studied as such, without drawing inferences from one’s knowledge of other languages was generally accepted in the research tradition called structuralism which dominated linguistic research in Europe and the USA during the 1930s – 1950s.
Most linguists today probably would place themselves somewhere between the extreme positions “all languages are essentially the same (so it is enough to study one)” and “all languages are essentially different (and one cannot make any generalizations)”. Languages vary widely in their structures, but there is also some common ground and that is the reason why we find similar structures and categories in different languages all over the world. The study of languages that have not been described before may reveal something completely new, but it will add also evidence for regularities that have already been discovered in other languages.
The quest for universals and the establishment of linguistic types
Features that are common to all languages are called linguistic universals. There are different approaches to their study and different understandings of universals. In the approach that uses the concept of “Universal Grammar” mentioned above, universals are abstract principles that underlie concrete structures. For example, there is assumed to be an abstract feature [tense] with a certain place in an abstract structure [VP] (the name VP comes from verb phrase). Overt markers of tense that correspond to this abstract feature are, for example, the English morphemes ‑ed and will in We walked in the park and She will come tomorrow. However, claiming that the abstract feature is part of Universal Grammar does not mean that in all languages of the world there must be an overt marker of tense.
Absolute universals (statements that are true for all languages) are usually fairly general, for example: “in all languages there are means to negate a statement”, or: “in all spoken languages there are vowels and consonants”. There are not many such general statements that really hold for all languages of the world. Some are disputed, for example, the question whether all languages have nouns and verbs as separate word classes. Furthermore, what we call a verb in one language may be very different from a verb in another language. The linguist Wolfgang Klein once wrote that using the term “verb” for such different phenomena as the verb in Latin and the verb in Chinese may be like using the same term with reference to rice and potato and calling rice the potato of the Chinese (Klein 1995: 81). We cannot even be sure that what is a verb in one language will also be translated by a verb in another language.
Find examples from languages where parts-of-speech differ from European languages on our Map: exercises for Iwaidja (ex. 3) or Hoocąk (ex. 2).
Another type of universals are implicational universals. They are stated in the form “if a language has feature A, then it also has feature B”. For example: “If a language has a dual then it also has a plural” – that means there is no language that marks nouns or pronouns for dual (meaning ‘two’) and not for plural (meaning ‘more than one’), but there are languages that have both a dual and a plural and languages that only have a plural. This kind of statement does not claim that all languages have feature B (in our example – that all languages mark nouns for plural). The search for implicational universals has brought to light many interesting regularities that characterize human languages.
In addition to universals in the strict sense (= what is true for all languages without exception), linguists are also interested in features that are found if not in all, then in the great majority of languages. Sometimes these features are called “statistical universals”, or, better, universal tendencies. For example, in most languages that have a preferred word order, the subject comes earlier in the clause than the object (see Chapter 3 Language Structures for details). Many implicational universals are universal tendencies rather than absolute universals.
The search for features that are common to all or most languages is complemented by cataloguing and systematizing the differences. This is what linguistic typology is concerned with (see also Chapter 1). To continue the example given above, a research question for linguistic typology is which number systems are found in the languages of the world, and the result of this research is the distinction of the following types: 1) languages that don’t mark number, 2) languages that distinguish singular and plural, 3) languages that distinguish singular, plural, and dual, and so on. Some typological investigations start with a simple yes/no-question, for example: Does a language mark past tense (that is, distinguish formally between the present and the past)? Such questions divide all the languages of the world into two groups. In the next step, the languages of one of the groups are considered further, for example by investigating further differences that are made in languages that mark past tense. Some of these languages distinguish between a remote past and a past further away from the moment of speech. The Amazonian language Yagua stands out by distinguishing five grades of remoteness: ‘a few hours ago’, ‘a day ago’, ‘about a week to a month ago’, ‘more than a month ago, up to two years’, and ‘a long time ago’ are all marked by different suffixes on the verb (find the details in Dahl & Velupillai 2013).
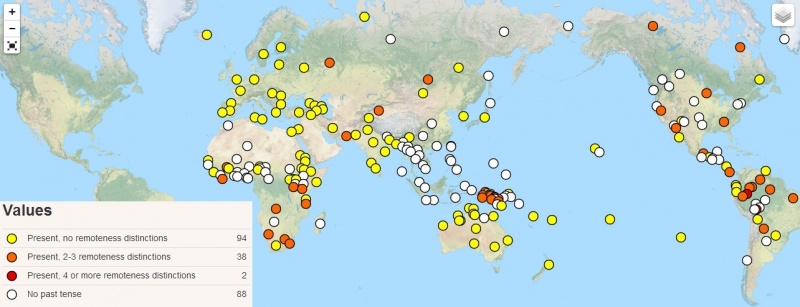
Past tense distinctions (Dahl & Velupillai 2013)
Certain linguistic features and types occur more often in some part of the world than in others. Interestingly, the geographic distribution of linguistic features often cuts through the classification of languages into families.
The World Atlas of Language Structures (WALS) shows and discusses the distribution of various features that have been studied by typologists (Dryer & Haspelmath 2013). The range of features that are presented is very large: it includes sounds (for example: Which languages have nasal vowels?; Where do we find tone languages?), words (for example: Which languages use the same word for ‘hand’ and ‘arm’?; Where does the word for ‘tea’ come from?), and grammar, and there is also a chapter about writing systems.
How can different languages be described and compared?
There are many possible ways of describing linguistic structures, words, sentences, or sounds. Different traditions have been established in different parts of the world, for example, there is a European tradition, an Indian tradition, an Arabic tradition. These traditions have sprung from the analysis and description of one or two particular languages, most often focusing on a literary variant – the language of sacred texts, or that of renown writers. The European tradition was founded by Greek grammarians and later developed further for the description of (written) Latin. Since the early Middle Ages this “Latin grammar” was then used as a model to describe first other European languages, and later on also non-European languages, for example, the native languages of the American territories conquered by Spain. The more the languages under description differed from Latin, the less suitable this method was for their description. The categories and structures known from Latin were supposed to be found in all languages, but other categories were often ignored – a good example for the wisdom that one finds only what one is looking for. For example, English was described as having an ablative (“of the book”) and a vocative case (“Oh book!”), while the use of the definite and the indefinite article was not treated at all (Latin didn’t have articles). Over the centuries the Latin tradition was slowly modified and adapted to better suit modern European languages. European national languages developed their own tradition, which nevertheless was (and is to this date) based on the Latin model.

A 18th century grammar of English – with a full declension of the word “man”
A serious challenge to the European tradition arose in the 20th century, when anthropologists and linguists in the USA became interested in native American languages and found that traditional European grammar was not suited for their description. The study of these languages was an important impetus towards the development of new methods of language description, and at the same time it triggered a new understanding of the motive and the aim of language descriptions, a new approach to “grammar”. In this new view, a grammar has to state objectively which forms and constructions are used by speakers of a language and must not judge which of these forms are “right” or “wrong”, “good” or “bad”. Every structure that native speakers of a language regularly use and accept is “right”. This view is in opposition to the traditional understanding that associates grammar with the literary standard of a language and the acceptance of structures by certain authorities, for example teachers.
Modern linguistic research (such as that behind the WALS) uses methods that are suitable for the description of very different linguistic structures and thus can be used with any language.
This can be seen most clearly in the description of the sound system of languages. The International Phonetic Alphabet (IPA), which was developed at the end of the 19th century, is a set of symbols that can be used to describe the sounds of all human languages. Its values have been fixed: each symbol stands for a sound that is produced in a certain manner of articulation (among others, by bringing one’s tongue and lips in a certain position). Letters of an alphabet, in contrast, are associated to sounds in words of particular languages. For example, the letter < r > stands for different sounds in English, Spanish, or French, and even within one language a letter may symbolize different sounds, for example the letter < a > in the English words has, was, ask. The IPA symbols [r] and [a] are unambiguous. Note that in this paragraph you can observe a convention used by linguists: to distinguish letters from sounds, different sorts of brackets are used.
Study question:
Find words in your native language where the same letter stands for different sounds.
Practical Tip
Many languages of the world have already been described using the symbols of the IPA. Knowing this system is very useful to people interested in the languages of the world. Learn the IPA here.
For a small sample of the sounds of a language that could then be compared with others, the International Phonetic Association created a simple version of a traditional tale – The North Wind and the Sun. The translation of this tale is read by a native speaker and the recording transcribed using the IPA. Find examples of The North Wind and the Sun (recording and transcription) here.
The common basis for describing the different sounds of human languages is the “device” by which they are produced that is common to all humans (the voice box, mouth, tongue, lips). Read more on this and on different sound systems in Chapter 4. It is much more difficult to find a common base for the description of words and grammatical structures. The latter will be discussed in Chapter 3, while the remaining part of the current chapter considers what is common and what is different in the vocabulary of the languages of the world.
Words and their meaning
In any fully functioning language one can express everything that the speech community needs to express. Obviously, different speech communities, but also groups within one speech community, may have different needs, and this is reflected in differences in the vocabulary. For example, Germans who like mushroom picking know many different names of mushrooms while the average German may know no more than three or four. Many interesting questions arise when comparing words across languages, for example:
- Which words are common to all languages? Are there such words? Do all languages have a word for …?
- Do words in different languages mean the same? How do they differ?
- Which differences are related to differences in culture? What can we learn about differences in culture by studying vocabulary?
- What may be the consequences of differences in the meaning of words? Are differences in vocabulary related to differences in thinking?
These questions will be addressed in this section.
Basic vocabulary
Several linguists have tried to devise a list of words that most probably have equivalents in all or almost all languages. These lists are often used to compare languages and to find similarities between two languages that are genetically related (belong to the same family). The most famous of these lists was started by the American linguist Morris Swadesh in the 1950s. There are several versions, ranging from about 100 to 200 words. Swadesh’s motivation was to provide a list of words that could be used to establish the degree of relationship between languages. Languages that are closely related (belong to the same branch or subgroup of one language family) share a large part of their vocabulary. Words that two or more languages have inherited from the same ancestor language are called cognates, for example English blood, Dutch bloed, German Blut, or Polish głowa, Croatian glava, Russian голова (golova) ‘head’. Cognates are found most easily in basic vocabulary: words for everyday concepts that are less dependent on cultural differences and not likely to be borrowed from other languages. The Swadesh list contains among others words for body parts (head, eye, blood), everyday human activities (eat, drink, see, walk), natural phenomena (sun, water, fire), small numbers (one, two, three), and personal pronouns (I, you, he).
Swadesh list
There follows a fragment of a Swadesh list. Which words may be cognates? Fragment from a Swadesh list for three languages of the Hokan or Yuman family (Native American languages spoken in California and Mexico)
| № | English | Ipai (Kumeyaay) | Kiliwa | Cocopa |
| 22 | One | ‘ehink, ‘uun | msíg | Shitt |
| 23 | Two | hewuk | juwak | Xwak |
| 24 | Three | hemuk | jmik | Xmuk |
| 25 | Four | chepup | mnak | Spap |
| 26 | five | sawrrup, saarap | salchipam | Ssrap |
| 36 | woman | siny | kekóo | s’ak |
| 37 | man (adult male) | ‘iikwich | kumeey | ‘apá |
| 64 | blood | ‘ehwatt | kujat | (ny)xwatt |
| 65 | bone | aq | ják | (ny)yak |
| 72 | head | hellytaa | iy | Mkur |
| 74 | eye | eyiiw | yuu | ‘iyú |
| 83 | hand | esally | sal | ‘isháálly |
| 84 | wing | wirewir | wálu | ‘irwír, ‘isháálly |
| 92 | to drink | wesii | chee | Ssi |
| 93 | to eat | wemaa, wesaaw | tmaa | Ma |
| 107 | to sleep | hemaa | smaa | Shma |
| 147 | Sun | ‘enyaa | eniaay | Nya |
| 148 | moon | hellyaa | ja’la’ | xlly’a |
| 150 | water | ‘ehaa | ja’ | Xa |
| 154 | sea (as in ocean) | ‘ehaasilly | ja’ tay (“big water”) | xakwss’ílly |
| 159 | earth (as in soil) | ‘emat | maat | Matt |
| 167 | fire | ‘aaw | a’aw | ‘a’á |
| 172 | red | ‘ehwatt | kwal | Xwatt |
| 175 | white | nemeshap | msaap | Xmaally |
| 176 | black | nyilly | nleeg | Nyiilly |
Using a method called lexicostatistics, Swadesh tried to calculate the degree of relationship between languages on the basis of the number of cognates found in his list. This approach is disputed in linguistics. On the one hand it offers a feasible method for historic comparison of languages of which we don’t have historic records. On the other hand it is doubtful how reliable this method is. For example, though it is true that basic vocabulary is less often borrowed from other languages, such borrowing can be found everywhere in the world. Without historic documents it is often not possible to determine whether similar words in two languages are the result of a common heritage or of borrowing.
Apart from language comparison, Swadesh lists and other collections of basic vocabulary are also used in language documentation. They are a useful tool and starting point for collecting vocabulary of a language.
Practical Tip:
Examples of these lists in various languages can easily be found on the Internet by searching for “Swadesh list”. Good places to start are Wikipedia (entry “ Swadesh list” in several languages), Wiktionary, and the Rosetta project, which hosts a growing collection of such lists in lesser used languages (search for “Swadesh”).
A weak point of these lists is that the point of departure is usually a collection of words in a certain language (most often English) that are then translated into other languages. This method works on the assumption that these words indeed can be translated and that the translation equivalents are more or less exact correspondences. However, this cannot be taken for granted. Even seemingly basic concepts such as ‘hand’ or ‘brother’ can be covered by very different words. While English distinguishes hand, arm, and finger, other languages use the same word for ‘hand’ and ‘arm’, or for ‘hand’ and ‘finger’ (see Brown 2013a and 2013b in WALS, http://wals.info/chapter/129 and http://wals.info/chapter/130). And while European languages usually have a word ‘brother’ designating a male sibling, other languages may make other distinctions. For example, in Samoan [3] a man or boy refers to a sister with the word afafine and to a brother with the word uso. But this last word (uso) is used also by girls and women to refer to a sister, while they call a brother tuagane. Thus the English words brother and sister cannot be translated into Samoan (or only in a clumsy way, saying for example that a brother is either tuagane or a male uso).
A more neutral way of collecting vocabulary is by defining topics, for example ‘body parts’, ‘kinship terms’, ‘natural phenomena’, ‘colour terms’, etc. and then collect the means of expression a given language uses for these topics and try to give their precise meaning without assuming that they have an exact equivalent in English (or whichever language is used for the description). This method is basically used in the project The Intercontinental Dictionary Series (IDS), where vocabulary belonging to 22 different topics is collected from a great variety of languages. The collection can be browsed at the site http://lingweb.eva.mpg.de/ids/.
Word meaning and categorization
When we learn another language we often find that the meaning of words is not exactly the same as in corresponding words in our mother tongue. Sometimes a word in one language combines the meaning of two words in another language. For example, English wood may refer to a place with many trees or to a material. German has two different words: Wald and Holz, respectively. In Latvian, on the other hand, the word koks refers to both the material and a single tree. Compare:
| a place with trees | material from trees | a tree | |
| English | wood | tree | |
| German | Wald | Holz | Baum |
| Latvian | mežs | koks | |
Such examples show that the vocabulary of a language is not an inventory of labels for things and phenomena that exist independently of the human mind. The categories that stand behind individual words are created and maintained by these words, by the way speakers use these words and contrast them with other words in their language.
Each individual language includes an invitation to look at the world in a certain way. What is lumped together in one language may be highly differentiated in another. For example, European languages usually use one verb for the action of transporting an object while holding it on some part of one’s body – in English this is the verb carry. Now look at some of the verbs that are used in ǂAkhoe Haiǁom [4] to express this meaning:
ǂAkhoe Haiǁom words for ‘carry’
ton ‘carry on one’s shoulder’ !guri ‘carry on one’s head’ ǁgobe ‘carry on one’s back’ aba ‘carry (a baby) on one’s back’ ǂkhore ‘carry a load’
We may say that ǂAkhoe Haiǁom (and many other languages of the world) invites us to see the different ways of carrying, depending on what is transported and how it is held, while languages such as English invite us to see the similarity of these actions. Knowing that there are different ways to look at something makes us wiser. None of these different ways is superior to others, all are reasonable and useful.
The categories defined by the meaning range of individual words are first and foremost lexical categories (related to words). A much disputed question is in which way they are related to conceptual categories, to categories of the mind, and how strong this relation is. Does the vocabulary of a given language determine the way speakers of this language perceive the world? Does language determine thought? Or is it merely a reflection of the way our mind works – and as our mind may work in different ways, there are different possibilities from which to choose when associating a word with a meaning?
The strong hypothesis that language determines perception has been proven untenable. The different lexical categories for the expression of ‘tree’, ‘place where trees grow’, and ‘material of trees’ do not indicate that speakers of English or Latvian see no difference between trees growing and the substance they consist of – after all, there are further words in these languages that single out smaller categories, such as English forest. Europeans are equally able to perceive the difference between carrying a sack on one’s shoulder and carrying a baby in one’s arms, or carrying a suitcase by its handle, while speakers of a language that has different verbs for each of these actions will not deny that they have something in common. These and similar examples from well-known languages should make us cautious when we hear about some exotic language whose speakers allegedly perceive the world completely different from Europeans because their words have different meanings.
A good case to study the relation between lexical categories and perception are words for colour. The languages of the world differ in the range of words denoting colours. For example, many languages use the same word for ‘blue’ and ‘green’ [5], other languages on the other hand have different words for colours that English lumps together as blue. However, experiments have shown that speakers of such different languages nevertheless perceive colours in the same way. Speakers of a language with one word for ‘blue’ and ‘green’ distinguish the colour of the sky as clearly from the colour of grass as speakers of English. Furthermore, the word they use for both (which linguists sometimes call “grue”) is not defined as something in-between green and blue (say, a shade of turquoise) or the changing colour of the sea, but rather as both the colour of the sky and the colour of grass. Even more striking for Europeans are languages with only two colour terms, where the colour of blood is named by a word that also means ‘white’ (or the one that also means ‘black’).
There is much more we can learn from the study of colour terms [6]. For example, there seems to be a universal tendency which colours are named most often by a simple, non-derived word (such as English red, but not golden, which is derived from gold). This tendency has first been described by Brent Berlin and Paul Kay in their book Basic color terms: Their universality and evolution (1969). The authors propose the following hierarchy (simplified here):
| first | black and white (both words are also used with reference to other colours) |
| then | red |
| then | green (or “grue”) and yellow |
| then | blue |
| then | brown |
| then | others (pink, orange, purple, grey) |
This means, for example, that if a language has only three basic colour terms, one of them will mean ‘red’ (but not ‘blue’ or ‘yellow’), or that if a language has a word for ‘blue’, it also has words for ‘red’, ‘green’, ‘yellow’, but not necessarily for ‘brown’ or ‘pink’.
Exercise
The web-site sorosoro.org includes short video clips presenting selected words in several endangered languages. Go to http://www.sorosoro.org/en/colors and watch the clips about colours in six languages of Central Africa (Akele, Baynuk, Benga, Menik, Mpongwe and Punu). How many and which colours are named in these clips? Do the inventories in these languages correspond to the hierarchy proposed by Berlin and Kay?
Words for the world we live in
Differences in vocabulary may reflect differences in culture and society and are therefore an interesting subject not only for linguistic investigations, but also for anthropology and cultural studies. Furthermore, words can be the carrier of traditional wisdom, of knowledge accumulated by a people through experience over a long time. In recent time also researchers from disciplines such as biology, medicine, or even astronomy have started to pay attention to lexical categories found in languages in different parts of the world. As Nettle and Romaine (2000: 60) put it: “The vocabulary of a language is an inventory of the items a culture talks about and has categorized in order to make sense of the world and to survive in a local ecosystem.” The preservation of endangered languages is part of the preservation of knowledge about local ecosystems, which in turn can be vital for the preservation of this ecosystem.
Probably all languages have a differentiated vocabulary for certain animals that are important for a community. In European languages we may find many words for cattle, with different terms for males and females (bull, cow), young ones (calf), and several distinctions regarding fertility and the use the animal has for humans (bullock, ox, heifer…). In Baka, the language of a community of hunter-gatherers in Central Africa, there are many different words referring to elephants [7]:

| Baka word | Explanation |
| ìjà | elephant in general |
| ndzàbò | very big male elephant, king of elephants |
| sɛ̀mɛ̄ | old big male elephant |
| kàmbà | big male elephant (but not as strong as the above) |
| mòsɛ̀mbì | male elephant (between kàmbà and mòbòŋgɔ̀) |
| mòbòŋgɔ̀ | smaller male elephant |
| èkwāmbē | young male elephant living alone; male or female elephant that has lost its mother and become solitary |
| lìkòmbà | female adult elephant |
| bèndùm | elephant calf |
To the Baka, elephants are an important source of food, and hunting elephants is an important activity (note that the Baka traditionally didn’t hunt elephants for ivory and that their need of elephant meat is not the cause that elephants have become an endangered species). The different terms for elephants of different strength reflect knowledge that is vital for the hunters.
The two examples above are concerned with differentiations within one species that are of direct importance to a given community. Another aspect is the amount of names for different species, which reflects a community’s awareness of the biological diversity surrounding them. Some of the most biodiverse places in the world are found in the Pacific. Thousands of different species of fish and other marine creatures live in the reefs of the Coral Triangle [8]. Languages spoken in that area usually distinguish between 300 and 500 different fish names (Pawley 2011: 269). Many species had long been known and named by local people before western scientists discovered and catalogued them. Recently the importance of that local knowledge has been recognized by biologists and conservationists. Lists of names of species in local languages complete lists of the Latin terms, and sometimes they are the better inventories.
Milne Baye conservation initiative
Watch a short clip about a conservation initiative on a small island of Milne Baye, Papua New Guinea, shot by James Morgan for USAID. At the beginning of the clip you see how a list of fish names is used in making an inventory of the species that have to be protected.


In another film by James Morgan about people of the Coral Triangle and the disastrous effects of blast fishing on the environment and on people, the following questions are posed:
- What is the future of marine conservation?
- What are we really trying to conserve?
- And who should we look to for the answer?
- Who really understands the ocean?
- And why aren’t we listening to these voices?
http://jamesmorganphotography.co.uk/film/the-bajau-laut
Biology and environmental studies are examples of fields where listening to local voices has been recognized as valuable for modern science. A related field is medicine: the knowledge of people about the healing capacities of local plants can be very important for the development of new pharmaceutical products. The key to access this traditional knowledge is language – very often, a language spoken by a small community that is endangered by cultural change and pressure from other, more powerful languages. Recall that the hotspots of biological diversity (and endangerment of species) coincide to a considerable extent with the hotspots of linguistic diversity (and language endangerment; see Chapter 1 on Languages of the world). Collaboration between members of local communities and scholars from various fields is needed to uncover and preserve this knowledge. Today, linguists, anthropologists and biologists often undertake field trips together and profit from each other’s knowledge and skills. Other disciplines that have become interested in local knowledge and local languages are geography (including cartography) and cultural astronomy (collecting names for stars and constellations, knowledge and myths about celestial objects, etc.). By documenting endangered languages and assisting in revitalization projects, linguists can also give something back to the community whose knowledge has been explored.
Also reflected in language are social structures within a community and relationships between its members. A classic field of research in cultural anthropology and in anthropological linguistics is kinship and the names for relations between members of a family. As speakers of a European language we may think that the kinship relations expressed by our terms for ‘father’, ‘brother’, ‘uncle’, ‘cousin’ etc. are basic and should be found anywhere in the world. In fact, kinship terminology varies greatly across cultures, but there is also some order in this variation: anthropologists have identified six basic types of kinship systems that can be found all over the world. They are called each after one of the languages where the type is found: the Hawaiian system, the Eskimo system, the Omaka system, the Crow system, the Iroquois system, and the Sudanese system. The Eskimo system is the one found in many European languages, including modern English. Old English, on the other hand, supposedly belonged to the Sudanese type, where there are different terms for father’s and mother’s brother (all “uncles” in the Eskimo type), and different terms for their children (all “cousins” in the Eskimo type). The system with the least terminological differentiation is the Hawaiian system: cousins are referred to by the same term as brothers and sisters (in Hawaiian kaikuahine for girls and kaikua’ana for boys), and in the parent generation there is one term for mothers and aunts (Hawaiian makuahine), and one for fathers and uncles (Hawaiian makuakane).
Learn more
Learn more about kin terms at one of these sites (tutorials for students of anthropology):
- Kinship Terminologies by Brian Schwiemmer, University of Manitoba; includes examples from real languages;
- Kinship. An introduction to Descent Systems and Family Organization, by Dennis O’Neil, Palomar College, San Marcos, California
Despite their diversity, kinship terms are relatively easy to classify and to compare across languages because they are based on some simple parameters: relation by blood or by marriage, generation, age, and gender. Kinship terms not only reflect the kin system of a given community, they also maintain the systems. Children acquire these words at a young age and develop an awareness of the relation named by the terms.
Find exercises at the Interactive Map for kinship terms Puma and Ilgar (ex. 4)
Activity
Watch a clip about kinship and the importance of family in an Australian aboriginal culture (the Yolngu people of Arnhem Land) at the site Twelve Canoes (when the coloured rectangles appear, choose the topic “kinship”).
Families are important in all human societies. But what exactly is a family? The meaning of the word for ‘family’ may be different both with respect to who belongs to a family and how important certain family ties are for individuals. One doesn’t have to go far away to study such differences, they can be observed even in neighbouring European countries such as Poland and Germany. There are many differences between the meaning of the Polish word rodzina and the German word Familie, although these words are treated as translation equivalents in dictionaries and in texts. In general, to Poles ‘family’ includes more persons and is of more importance for an individual than it is for Germans. An anecdote says that in international language courses where each participant has to speak about the topic “my family”, Polish participants always take the longest time. In German a grown up person may say “Ich habe keine Familie” (‘I don’t have a family’), meaning that he or she is not married and doesn’t have children. Translated into Polish, this sentence would imply that the speaker is completely alone in the world, without parents, sisters, brothers, without a single uncle, aunt, or cousin. Also other social relations such as friendship have different meanings in different cultures, which may be reflected in the vocabulary or in the meaning and use of individual words. In Polish there are two words for ‘friend’, przyjaciel (female przyjaciółka) and kolega (female koleżanka), and for someone learning Polish as a second language it is not easy to find out to which category their new Polish friends belong. There are also differences within one language, when it is spoken in different societies: the English word friend has different meanings in England, the USA, or Australia.
Anna Wierzbicka, a Polish linguist who has lived and worked in Australia since 1972, has discussed these issues in several of her works. She emphasizes the importance of a careful study of word meaning for comparative sociological and psychological studies:
“Consider, for example, the following question: how do patterns of friendship differ across cultures? One standard approach to this question is to use broad sociological surveys based on questionnaires, in which respondents are asked, for example: How many friends do you have? How many of them are male and how many female? How often, on average, do you see your friends? […] The procedure seems straightforward – except for one small point: if the question is asked in Russian, or in Japanese, what word will be used for friend? The assumption behind such questionnaires, or behind comparative studies based on them, is that, for example, Russian, Japanese, and English words for friend can be matched. This assumption is linguistically naive and the results based on it are bound to present a distorted picture of reality.” (Goddard & Wierzbicka 1995: 59)
Another example Wierzbicka gives are emotions. She argues that the labels for emotions (such as English fear, anger, happiness) are language specific and culture specific and as a rule do not have exact matches in other languages. From her own experience as a bilingual she reports that even after having lived for a long time in an English speaking community in Australia, she still categorizes (and experiences) her feelings with Polish expressions such as żal and przykro, terms that only roughly may be translated by English sorry, but include various nuances specific to Polish culture (Wierzbicka 2001).
Some words have a special significance in a given culture, as they label concepts that are important parts of this culture. Such words have been called (by Wierzbicka and others) “keywords of culture”. The detailed study of these keywords, their meaning and use, gives us insights into different cultures – also our own.
Study question
What could be a “keyword of culture” in your native language? Why? What is special about it – what does it include that is not easily translated into other languages?
In the previous section, when discussing colour terms or different words for ‘wood’, or for ‘carry’, we rejected the thesis that lexical categories (the meaning of words) determine the way people perceive the world and think about it. In this section we argued that the vocabulary of a language reflects the natural and social environment of a speech community. These two approaches may be reconciled, as in the quote from Goddard & Wierzbicka, to which we would do well to subscribe:
“Culture-specific words are conceptual tools which reflect a society’s past experience of doing, and thinking about things in certain ways; and they help to perpetuate these ways. As a society changes, these tools, too, may be gradually modified and discarded. In that sense the outlook of a society is never wholly ‘determined’ by its stock of conceptual tools, but it is clearly influenced by them. Similarly, the outlook of an individual is never fully ‘determined’ by the conceptual tools provided by his or her native language, because there are always alternative ways of expressing oneself, but one’s conceptual perspective on life is clearly influenced by his or her native language.” (Goddard & Wierzbicka 1995: 58).
Let’s Revise! – Chapter 2
Go to the Let’s Revise section to see what you can learn from this chapter or test how much you have already learnt!
Notes
[3] Samoan data by courtesy of Ulrike Mosel.
[4] Source: ǂAkhoe Haiǁom word list (2010). The letters ǂ, ǁ, and ! represent clicks (see Chapter 4: The Sounds of Language)
[5] The Wikipedia entry “Distinction of blue and green in various languages” discusses many examples. The map number 134A in WALS shows the distribution of different ways to express ‘green’ – by a separate word, by a term for both ‘blue’ and ‘green’, and other possibilities.
[6] Readers interested in this topic are referred to the first chapter in Taylor (1995) and to the World Color Survey at the University of Berkeley. See also the WALS Chapter on Basic Colour Categories by Kay & Maffi 2013.
[7] Baka spoken in Gabon, Source: Paulin 2010: 294.
[8] “The Coral Triangle is a geographical term so named as it refers to a roughly triangular area of the tropical marine waters of Indonesia, Malaysia, Papua New Guinea, Philippines, Solomon Islands and Timor-Leste that contain at least 500 species of reef-building corals in each ecoregion.” Wikipedia, “Coral Triangle“, accessed 30.08.2014.
References & further reading
- Bartmiński, Jerzy. 2006. Językowe podstawy obrazu świata. Lublin: Wydawnictwo Uniwersytetu Marii Curie –Skłodowskiej.
- Brown, Cecil H. 2013a. Finger and hand. In: Dryer, Matthew & Haspelmath, Martin (eds.), The World Atlas of Language Structures Online. Munich: Max Planck Digital Library, chapter 130. Available online at http://wals.info/chapter/130.
- Brown, Cecil H. 2013b. Hand and arm. In: Dryer, Matthew & Haspelmath, Martin (eds.), The World Atlas of Language Structures Online. Munich: Max Planck Digital Library, chapter 129. Available online at http://wals.info/chapter/129.
- Dahl, Östen & Velupillai, Viveka. 2013. The Past Tense. In: Dryer, Matthew S. & Haspelmath, Martin (eds.) The World Atlas of Language Structures Online. Munich: Max Planck Digital Library, chapter 66. Available online at http://wals.info/chapter/66.
- Dryer, Matthew & Haspelmath, Martin, eds. 2013. The World Atlas of Language Structures Online. Munich: Max Planck Digital Library. Available online at http://wals.info.
- Goddard, Cliff & Wierzbicka, Anna. 1995. Key words, culture and cognition. Philosophica 55: 37-67.
- Kay, Paul & Maffi, Luisa. 2013. Number of non-derived basic colour categories. In: Dryer, Matthew S. & Haspelmath, Martin (eds.) The World Atlas of Language Structures Online. Munich: Max Planck Digital Library, chapter 132. Available online at http://wals.info/chapter/132.
- Klein, Wolfgang. 1995. Das Vermächtnis der Geschichte, der Müll der Vergangenheit. Zeitschrift für Literaturwissenschaft und Linguistik 100: 77-101.
- Nettle, Daniel & Suzanne Romaine. 2000. Vanishing voices. The extinction of the world’s languages. Oxford: Oxford University Press.
- Pawley, Andrew. 2011. What does it take to make an ethnographic dictionary? On the treatment of fish and tree names in dictionaries of Oceanic languages. In: G. Haig et al., eds. Documenting endangered languages. Berlin: de Gruyter Mouton, 263-287.
- Paulin, Pascale. 2010. Les Baka du Gabon dans une dynamique de transformations culturelles. Perspective linguistques et anthropologiques. Thése du doctorat, Université Lumiere Lyon 2. [available on-line at: http://www.ddl.ish-lyon.cnrs.fr/fulltext/Paulin/Paulin_2010_These.pdf]
- Taylor, John R. 1995. Linguistic categorization. Oxford: Oxford University Pres.
- Wierzbicka, Anna. 1997. Understanding cultures through their key words: English, Russian, Polish, German, and Japanese. New York: Oxford University Press.
- Wierzbicka, Anna. 2001. A culturally salient Polish emotion: przykro. In: J. Harkins & A. Wierzbicka, eds. Emotions in crosslinguistic perspective. Berlin, New York: Mouton de Gruyter.
- ǂAkhoe Haiǁom word list. Based on Tertu Heikkinen’s wordlist. Adapted by Thomas Widlok, Christian Rapold and Gertie Hoymann. Expanded by Gertie Hoymann. Work in Progress. March 2010. [available online at the DoBeS archive, node: ǂAkhoe Haiǁom -> DoBeS -> Unsorted Sessions -> Akhoe Word List.]