Book of Knowledge
Chapters: 1 2 3 4 5 6 7 8 9 10
List of all languages referred to in the Book of Knowledge and other sections of the website.
DOWNLOAD and print out the Book of Knowledge.
Let’s Revise! – Chapter 3
Go to the Let’s Revise section to see what you can learn from this chapter or test how much you have already learnt!
Chapter author: Nicole Nau
Chapter contents:
Words in texts
Words in spoken language
The inner structure of words
Word order
Polar questions
How to express possession
How to show the structure of words and clauses
Notes
References & further reading
Languages differ in the way meaningful elements are put together: how words are made up and how they are combined into sentences. The branch of linguistics that studies the formal make-up of words is called morphology, while the combination of words into phrases and of phrases into clauses is studied in syntax. This chapter considers the structural diversity found in the languages of the world and introduces some basic terms and techniques for its description.
Words in texts
Texts consist of words, but in order to understand or produce a text in any given language one has to know more than the meaning of individual words. Words may appear in different forms according to their function in a clause, and various techniques are used to combine word-forms. We cannot translate a text from one language into another by translating word after word. Languages differ with respect to how much and what kind of information can (or must) be packed into one word. Therefore, the number of words used to express one and the same meaning varies greatly across languages. Compare the headline of the Universal Declaration of Human Rights in Estonian and Tok Pisin! One can see at once that these languages use very different techniques. Differences can also be observed in closely related languages, such as German and Dutch.
| Language | ‘Universal declaration of human rights’ [1] | Word count |
| Estonian | Inimõiguste ülddeklaratsioon | 2 words |
| Tok Pisin | Toksave long ol raits bilong ol manmeri long olgeta hap bilong dispel giraun | 13 words |
| German | Allgemeine Erklärung der Menschenrechte | 4 words |
| Dutch | Universele verklaring van de rechten van de mens | 8 words |
Analyzing these examples we find two reasons for the different number of words. On the one hand, what are separate words in one language may be expressed by a compound in another language: ‘human rights’ in German is Menschenrechte, composed of Menschen ‘people’ and Rechte ‘rights’. Estonian likewise combines the nouns inimene (root inim -) ‘man, human being’ and õigused ‘rights’ into one word. The meaning ‘universal declaration’ is also expressed by a compound in Estonian (ülddeklaratsioon). New words can also be made by derivation – for example, the English adjective universal is derived from the noun universe (more examples for compounding and derivation will be given below).
On the other hand, languages may use more or less function words – small words that are used to link words or phrases together, or to express grammatical meaning, for example plural or definiteness. In the Dutch example, the preposition van ‘of’ has such a linking function, and de is the definite article: de rechten van de mens literally translates “the rights of the people”. In Tok Pisin the equivalent of Dutch van or English of is the word bilong. The Tok Pisin word ol marks the plural, for example: buk ‘book’ – ol buk ‘books’. This plural marker is also found in the example above: ol raits bilong ol manmeri ‘rights of people’ = ‘human rights’. Words that express concepts like ‘man’, ‘rights’, ‘declare’, ‘speak’, ‘universal’, on the other hand, are called content words.
Broadly speaking, there are two possibilities for expressing grammatical meaning: by separate function words (as Dutch van, de, English of, the, Tok Pisin ol, bilong) or by inflection of content words, that is by changing their form, for example by adding or subtracting an ending. Polish and Hungarian are examples of languages that mainly use inflection.
| ‘Universal declaration of human rights’ | |
| Polish | Powszechna deklaracja praw człowieka |
| Hungarian | Az emberi jogok egyetemes nyilatkozata |
The Polish example contains four content words (‘universal’, ‘declaration’, ‘rights’, ‘man’), each in an inflected form that shows its function in the phrase and its relation to other words. The last word, człowieka, is the genitive singular of człowiek ‘man’, formed by adding the suffix – a to the basic form: człowiek-a ‘of (the) man’. The word-form praw is the genitive plural of prawo ‘right’ (here, the basic form praw-o has an ending, while the genitive plural form does not): praw ‘of (the) rights’, praw człowieka = ‘of human rights’, equivalent to Dutch van de rechten van de mens.
In the Hungarian version we find one function word (the definite article az) and four content words ‘human’, ‘rights’, ‘universal’, ‘declaration’). Plural is marked by a suffix on the noun: jog-ok ‘rights’ (jog ‘right’). The relation between ‘declaration’ and ‘human rights’ is marked on the word nyilakozat-a ‘declaration’ by the suffix -a. (See below: Possession)
Not only content words, but function words may also be inflected. This can be seen in German: in the phrase (Erklärung) der Menschenrechte ‘(declaration) of the human rights’ the word-form der is the genitive plural form of the definite article; in the nominative it has the form die. Compare: die Menschen ‘the humans’ / der Menschen ‘of the humans’, die Rechte ‘the rights’ / der Rechte ‘of the rights’, die Menschenrechte ‘the human rights’ / der Menschenrechte ‘of the human rights’.
Exercise
Compare translations of Universal Declaration of Human Rights, find function words in different languages! View or download this exercise here.
Words in spoken language
For texts written with a modern alphabetic script, words can be defined easily: a word is a string of letters separated from other strings by spaces or punctuation marks. More precisely such a string is called a graphic word. Some doubts may arise in cases such as English I’m (= I am), I’ve (= I have) or he’s (= he is). In speech, however, the doubtful cases are often more numerous than the clear cases, and it is quite difficult to define the borders of words exactly. Determining what should be written as one graphic word and what should be written separately is one of the first difficult tasks when developing an orthography for a formerly unwritten language (see also: Writing), and even for languages with a long tradition of writing there often remain points of disagreement. The notion of word and the distinction made above between function words and inflection are idealizations that work best for written language.
Study question
Find cases in your native language (or another language you know well) where the boundary of words is not clear.
Function words are often short and only weakly stressed and therefore tend to fuse with a neighbouring word. An element that always fuses in that way with another word without really becoming part of it is called a clitic. Examples from English are <’s>, <’ve> and <‘m>. Clitics differ from suffixes in that they can attach to different words – suffixes are usually specialized for a part of speech (verb, noun, or adjective) and have a fixed place. However, there is no fixed boundary: in the course of time a function word may become a clitic (for example English <am> becomes <’m>) and a clitic may become a suffix. Consider the following example from Polish (see below for the technique used in these and following examples and the meaning of the abbreviations):
śpiewa-ł-a= by ‘(she) would sing’
sing-pst-f=cond
gdy= by śpiewa-ł-a ‘If she sang…’
if=cond sing-pst-f
The past tense marker -ł- and the feminine marker -a- have a fixed place in the verb-form, while the conditional marker -by can attach to the verb-form or to a conjunction. In earlier times this element was a function word, now it is a clitic on the way to becoming a suffix.
The inner structure of words
Words may contain several components. The smallest units of a word that bear a meaning are called morphemes. “Meaning” here includes grammatical meaning. For example, the word-form rights contains two morphemes, the root (right) and the plural marker (-s). The word unbelievable contains three meaningful elements (morphemes): the prefix un (negation), the root believ(e), and the suffix able (element for building adjectives from verbs). A morpheme can have different forms of expression. For example the forms < un > (in unbelievable), < in > (in incredible) and < im > (in impossible) are different forms of the same morpheme. The concrete spoken or written form of a morpheme is called a morph. Thus it would be more correct to say: the word-form < rights > contains two morphemes that are expressed by the two morphs < right > and < s >. If a morpheme has several forms, they are called allomorphs: in written English the prefixes< in > and< im > are allomorphs of one morpheme. On the other hand, the < in > in < incredible > and the < in > in < income > are morphs that belong to different morphemes because they express different meanings.
| The following types of components of a word are commonly distinguished: | |
| root | a morph(eme) bearing a lexical meaning (right-s, un-believ-able) |
| suffix | a morph that follows a root (right-s, unbeliev-able) |
| prefix | a morph that precedes a root (un-believable) |
| affix | a cover term for suffix, prefix, prefix etc. (see below) |
| (inflectional) ending | the last suffix that expresses a grammatical meaning (right-s, untouchable-s) |
| stem | the part of a word to which an inflectional ending is attached, if there is one; a stem may contain only the root (right-), a root plus one or more affixes (untouchable-), or more than one root with or without affixes (German Menschenrecht-, Estonian inimõigus-) |
Word-formation
The word word is ambiguous: it may refer to a certain form that is part of a spoken or written text (for example, if we count the words of a text), or it may refer to a more abstract unit of meaning and form (for example, when we say that < book > and < books > are forms of the same word). A technical term for “word” with the second meaning is lexeme, but what we see in a text are word-forms. The building of word-forms that belong to one lexeme is called inflection. The building of words in the sense of lexeme is called word-formation.
One way of building words (lexemes) is by compounding. A compound is the combination of two (sometimes more) roots in one word. We saw above German Menschenrechte and Estonian inimõigused ‘human rights’. Some compounds can also be found in the Tok Pisin example: toksave ‘declaration’ contains the roots tok ‘speak’ and save ‘know’; manmeri ‘people’ consists of man ‘man’ and meri ‘woman’. Further examples:
| Language | compound | meaning | components |
| Teop | beiko moon | ‘girl’ | beiko ‘child’ + moon ‘woman’ |
| Logba | iwónɖú | ‘honey’ | iwó ‘bee’ + nɖú ‘water’ |
| Sheko | bōw kuʈʂu | ‘palm’ (of the hand) | bōw ‘belly’ + kúʈʂú ‘hand’ |
| yārb suku | ‘vein’ | yārbm̄ ‘blood’ + súkú ‘rope’ | |
| ʂūbū bambù | ‘grave’ | ʂūbū ‘death’ + bambù ‘pit’ |
Go to the Interactive Map and try exercises on compounds in Wilamowicean.
In many languages words (lexemes) are built by adding suffixes or prefixes to a root or to a stem. This way of building words is called derivation. For example:
| Hungarian | ember ‘man’ (noun) -> ember-I ‘human’ (adjective) |
| Polish | prawo (root praw -) ‘right; law’ -> praw-nik ‘lawyer’ |
| Dutch | verklar- ‘declare’ (verb stem) -> verklar-ing ‘declaration’ (noun) |
More examples and other techniques of derivation will be presented below.
Word-formation can be a “shortcut” to express a meaning which otherwise had to be described using several words. For example, the meaning of the Choctaw word tononoli, derived from tonoli ‘to roll’, is expressed in English as to roll back and forth. On the other hand, in the Tok Pisin text of the Universal Declaration of Human Rights, the meaning ‘universal’ is expressed as long olgeta hap bilong dispel giraun, literally ‘at all places of this world’.
Techniques for building words and word-forms
Several formal means are used in inflection and derivation. Most widespread is the use of affixes, especially suffixes (elements that follow a root) and prefixes (elements that precede a root), for example:
| Language | base | forms with suffix, prefix, or both |
|
íík’ ‘be old’ (verb) sūb ‘be red’ (verb) ʒááʒ ‘be good’ (verb) |
ííkńs ‘old’ (adjective) sūbm̄s ‘red’ (adjective) ʒééǹʃ ‘good’ (adjective) |
|
|
khim ‘house’ |
uƞkhim ‘my house’, kakhim ‘your (sg.) house’ |
|
|
gbla ‘teach’ zɔ ‘sell’ |
ɔgblawo ‘teacher’ ɔzɔwo ‘seller’ Note: ɔ- is a prefix and -wo is a suffix |
Another type of affix is the infix, which is inserted into a root, for example:
| Language | base | forms with infix |
|
peelh ‘to sweep the floor’ tɛk ‘to hit’ chrɛɛt ‘to comb’ |
prneelh ‘broom’ trnɛk ‘hammer’ chnrɛɛt ‘comb’ |
|
|
|
máni ‘he sings’ aphé ‘he hits’ hoxpé ‘he coughs’ |
mawáni ‘I sing’ awáphe ‘I hit’ howáxpe ‘I cough’ |
While an infix splits the base, a transfix (also called confix) is itself split into parts that are inserted into the root. This kind of morphological process is found in Semitic languages (Arabic, Hebrew). Various vowels are inserted into a root of consonants, sometimes prefixes or suffixes are added. For example, in Egyptian Arabic the root meaning ‘write’ is k-t-b, and examples of word-forms are k a t a b ‘he wrote’, k i’ t aa b ‘book’, mak ’ t a b a ‘bookshop’, mak ’ t uu b ‘written’ (Bauer 1988: 25).
Go to the Interactive Map and try exercises on affixes in Yeri.
Reduplication is the repetition of a word or parts of a word. This technique is very widespread in the languages of the world. In Europe it is rare, but it is found, for example, in some Latin verbs that build the perfect stem by reduplication of the first part of the word. Reduplication may also affect a part from the middle of a word, as in the examples from Choctaw below. Data from languages from all over the word are collected in the Graz Database on Reduplication. You can find more information on reduplication in the languages of the world in Chapter 27 of the WALS (World Atlas of Linguistic Structures).
| Language | form without reduplication | form with reduplication |
| Latin | curr-o ‘I run’ tend-o ‘I span’ pung-o ‘I sting’ |
cucurr-i ‘I have run’ tetend-i ‘I have spanned’ pupung-i ‘I have stung’ |
| Choctaw | tonoli ‘to roll’ binili ‘to sit’ |
tononoli ‘to roll back and forth’ bininili ‘to rise up and sit down’ |
| Amele | ana ‘where’ me ‘good’ ʔela ‘long’ dahing ‘ears’ eben ‘hands’ gasuena ‘he searches’ |
anaana ‘wherever’ meme ‘very good’ ʔeʔela ‘very long’ dadahing ‘the ears of everyone’ ebeben ‘the hands of everyone’ gasu-gisu-ena ‘he searches repeatedly’ |
Go to the Interactive Map and try exercises: on reduplication in Totoli and in Teop.
Another technique used in inflection and derivation is the modification of a stem. This includes the following phenomena:
-
ablaut, where a vowel changes within the base: English man – men, sing – sung, sing – song;
-
consonant alternation at the end or the beginning of a stem (English believe (verb) – belief (noun)). Consonant alternation at the beginning of a stem is typical for Celtic languages, for example Welsh cartref ‘home’ – gartref ‘at home’;
-
change of stress: English ‘import (noun) – im’port (verb);
-
change of tone in tonal languages. Look at the examples from Logba and Sheko, where tones (in writing indicated by accents) mark grammatical categories such as tense or person:
| Language | example | |
| Logba | Matúkpí ubón adzísiadzí. Matukpí ubón adzísiadzí. |
‘I was going to farm every day.’ ‘I go to farm every day.’ |
| Sheko | Ṃbaadúra hadùfù. Ḿbaadúra hádùfù. |
‘Did you hit my younger brother?’ ‘Did he hit our younger brother?’ |
Two or more techniques may be combined, for example suffixation plus consonant alternation plus vowel alternation. In Polish the nominative singular of the word meaning ‘wood’ is las, pronounced [las]. The locative form is built by adding the suffix -e, changing the vowel from [a] to [ɛ] and the final consonant from [s] to [ɕ]: w lesie [lɛɕɛ] ‘in the wood’.
Go to the Interactive Map and try exercises on consonant alternation in Celtic languages.
Grammatical categories
Function words, affixes and the other techniques for building word-forms described above are used to express grammatical categories, such as number (singular, plural), tense (past, present, future), or case (nominative, accusative, dative). One of the characteristics of grammatical categories is their obligatory use in a certain language. For example, in many European languages nouns are always marked for number: we either talk about (a/the) book or books. In many languages of Australia or North America, on the other hand, nouns are not marked for number, or only some nouns are. For example in Warrgamay (Australia), ƞulmburru may mean ‘woman’ or ’women’ (Corbett 2001: 84, citing Dixon 1980).
Another example for a category that is obligatory in some languages but not in others is definiteness. If we want to translate the Polish sentence Kupiłam książkę into English, we have to decide between I bought a book and I bought the book. This shows us that in English definiteness (the difference between a book and the book) is a grammatical category, while in Polish it is not. We may say in Polish (and in English) things like Kupiłam tę książkę ‘I bought that book’ or Kupiłam jakąś książkę ‘I bought some book’, but this is not the same as the obligatory and regular choice between definite and indefinite article in languages like English or German.On the other hand the Polish sentence tells us that the “I” who bought the book is female – a man would have said Kupiłem książkę. This is because gender (masculine, feminine, neuter) is a grammatical category in Polish that has to be marked in past tense forms of verbs (as well as on adjectives and pronouns), while in English gender is not a grammatical category. If we want to translate the English sentence I bought a book into Polish, we have to know whether the speaker is a man or a woman in order to build the verb form – there is an obligatory choice between -a- and -e- in the frame kupił_m ‘I bought’. In English gender is important only in the choice of the third person pronoun: He bought books vs. She bought books. Hungarian in turn does not make this distinction, both these sentences are translated as (ö) vett könyveket, where ö may mean ‘he’ or ‘she’ (and it is not necessary in this sentence).
There are many different grammatical categories of which individual languages make their choice. Nevertheless, we find the same categories in many languages all over the world. The most widespread categories are: person, number, gender, definiteness, case, tense, aspect (e.g. perfective, imperfective, continuous), mood (e.g. imperative, conditional), voice (e.g. active, passive), and some others that are not known in western European languages. For each category, there is again a limited choice of options. For example regarding number, most languages distinguish between singular (one) and plural (more than one), but some languages make more distinctions: singular (one) – dual (two) – plural (more than two), or singular (one) – paucal (few) – plural (many). We will now look in more detail at two of these categories: person and gender.
Person
The category of person is concerned with participation in the speech act. It is formally marked in personal pronouns (I, you, we …) and/or in personal forms of verbs, for example in Polish: kocham ‘I love’, kochasz ‘you (sg.) love’, kocha ‘he/she loves’, kochamy ‘we love’, kochacie ‘you (pl.) love, kochają ‘they love’. Most often we find a threefold distinction, called first person = the speaker (I), second person = the addressee (you), and third person = other persons or things not participating in the speech act (he, she, it, they). This system is often combined with a twofold number distinction (singular vs. plural) so that, for example, ‘we’ is defined as first person plural. However, this is not precise – we is not the plural of I in the way trees is the plural of tree. It usually does not refer to several speakers but to a combination of the speaker with someone else, either with a second person or a third person. In English the question Will we meet again? may mean ‘will you and me meet again?’ (first + second person) or ‘will (s)he and I meet again?’ (first + third person), depending on the context where it is uttered. The first meaning is called inclusive (because the addressee is included), the second exclusive. Many languages distinguish these meanings by different pronouns. For example in Chamorro there are two words for ‘we’: ta (inclusive, i.e. ‘you and I’) and in (exclusive, ‘I and he/she’). Read more about this distinction in WALS, Chapter 39 and 40 (Cysouw 2013a, 2013b).
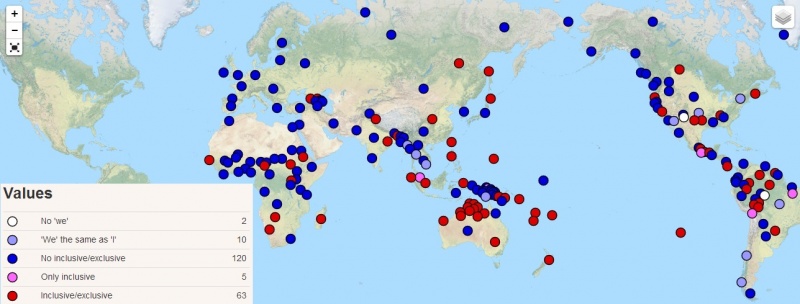
Inclusive/Exclusive Distinction in Independent Pronouns (Cysouw 2013a)
If the inclusive vs. exclusive distinction is combined with a number distinction of singular vs. dual vs. plural, we get still more possibilities. Compare the following sentences in Puma, which are different ways to say ‘we eat rice’, depending on whether the addressee is included or not and whether two or more people are referred to:
| ‘We eat rice’ | where ‘we’ = | category label |
|
keci roƞ caci |
‘you (sg.) and I’ |
dual inclusive |
|
ke roƞ cee |
‘you and I and at least one other person’ |
plural inclusive |
|
kecika roƞ cacika |
‘(s)he and I’ |
dual exclusive |
|
keka roƞ ceeka |
‘they and I’ |
plural exclusive |
*Note: the first word is the personal pronoun (‘we’), the last word is the verb ‘eat’ inflected for person.
Go to the Interactive Map and try the exercise no. 4 for Daakaka (Vanuatu).
Gender (noun class)
In European languages gender most often is manifest as a distinction between masculine and feminine, or between masculine, feminine and neuter. In other parts of the world we also find languages with four and five genders. The Nigerian language Fula even distinguishes twenty classes. On the other hand, many languages of the world do not distinguish noun classes at all. In The World Atlas of Language Structure (Corbett 2013), we find the following information: In a sample of 257 languages from all over the world, 145 did not have gender as a grammatical category (as Hungarian and English), 50 languages had two genders (in Europe for example French and Latvian), 26 languages showed three genders (as do Polish and German), 12 four and 24 five or more. Languages with more than five classes are found most often in Africa, but also in Papua New Guinea and Australia.
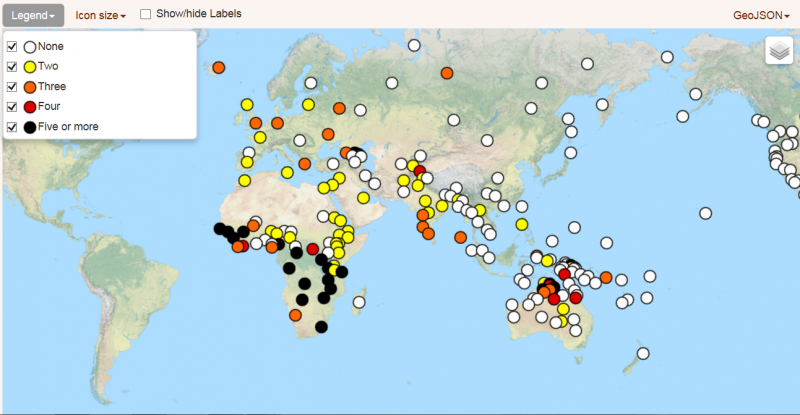
Number of genders in the languages of the world (Corbett 2013)
The “idea” behind gender is that nouns belong to different classes and that this is reflected in agreement, that is, in the form of other words in the same phrase or clause. The grouping of nouns into such classes (genders) may have a semantic motivation, for example nouns denoting human beings belong to one class, nouns denoting trees belong to another class and so on. The traditional terms “gender”, “masculine”, “feminine” are based on the fact that in European languages nouns denoting human beings and some animals belong to different classes according to the gender of the referent (the word for ‘man’ is masculine and the word for ‘woman’ is feminine). But for most nouns gender assignment lacks semantic motivation, it is a purely grammatical classification. In Polish, for example, the word książka ‘book’ belongs to the feminine class, while czasopismo ‘journal’ is neuter and artykuł ‘article’ is masculine. The following sentences show how adjectives, pronouns and some forms of verbs agree in gender with the respective noun:
Ten dobr-y artykuł został wydan-y już dawno. ‘This good article was published long ago.’
Ta dobr-a książka został-a wydan-a już dawno. ‘This good book was published long ago.’
To dobr-e czasopismo został-o wydan-e już dawno. ‘This good journal was published long ago.’
“Noun class” is a more neutral term than “gender”, because it avoids association with natural gender (sex). The individual classes may be simply counted as “class 1”, “class 2” and so on. The following examples are from Yimas, a language with 10 classes. The suffixes on the words for ‘my’ and ‘big’ show that the words for ‘foot’, ‘basket’ and ‘voice’ belong to different classes, just as in the Polish example the words for ‘article’, ‘book’ and ‘journal’ did:
| namtampara | amana | kpa | ‘my big foot’ |
| foot | my:class9.sg | big:class9.sg | |
| antuk | amana-wƞ | kpa-wƞ | ‘my loud voice’ |
| voice | my-class10.sg | big-class10.sg | |
| impran | amana-m | kpa-m | ‘my big basket’ |
| basket | my-class7.sg | big-class7.sg |
Go to the Interactive Map and try exercises on Noun classes in Logba (Ghana)
Classifiers
Another device where a classification of nouns is reflected in grammar is the use of classifiers. Classifiers are function words that are used in certain constructions with nouns. A typical construction where classifiers are found is with numerals, as in the following examples from the Austronesian language Minangkabau, spoken in Indonesia:
| sar-urang one-clf |
padusi woman |
‘one woman’ | |
| duo two |
ikue CLF |
anjiang dog |
‘two dogs’ |
| tigo three |
batang CLF |
pituluik pencil |
‘three pencils’ |
We may try to imitate this construction as “one person woman”, “two animal dog”, “three object pencil”, but we have to keep in mind that the words urang, ikue, batang in Minangkabau are function words, not nouns.
Several languages from North America use classifiers that point to the object of a verb. In such languages, the verb meaning ‘give’ has different forms depending on what is given. In the examples below from Cherokee the classifier is put into the sequence gà-____-nèè’a which means ‘she is giving him’ (the first word in each line is the noun denoting the object – ‘cat’, ‘water’, ‘shirt’):
| Wèésa | gà- káà -nèè’a | ‘She is giving him a cat’ (káà for living beings) |
|
Àma |
à- nèèh -nèè’a | ‘She is giving him water’ (nèèh for liquids) |
| Àhnàwo | gà- nʊ́ʊ́ -nèè’a | ‘She is giving him a shirt’ (nʊ́ʊ́ for flexible objects) |
Word order
In most languages the order in which words are combined to phrases and clauses is important: there may be only one possibility, or different orders have different meanings. English is very strict in allowing only the order subject – verb – object in transitive clauses. For example, we can only say He loves me, but not *Loves he me, *Me loves he, *He me loves etc. (The asterisk indicates that the construction is not grammatically correct, or possible only in very restricted contexts, for example, in a poem). In German, the most important rule for simple declarative sentences is that the verb be the second element of the clause. Both Er liebt mich and Mich liebt er are grammatically correct sentences. If we add another word, for example vielleicht ‘maybe’, we can form the correct sentences Vielleicht liebt er mich ‘maybe he loves me’, Er liebt mich vielleicht or Mich liebt er vielleicht, but not *Vielleicht er liebt mich with the verb in the third position. The difference between the German sentences Er liebt mich and Mich liebt er is that in the second variant the object (mich ‘me’) is emphasized, while the first variant is neutral with respect to emphasis. Many languages use word order in clauses for emphasis, usually together with a distinctive intonation. If a simple shift of word order is not possible, there may be special constructions which allow to place the object at the beginning of the sentence, for example in English It’s me he loves or I am the one he loves. The order which is (most) neutral with respect to emphasis is called “basic word order”.
Linguists have investigated the basic word order of simple sentences and found out that there are certain regularities. In simple sentences with the three elements subject (S), object (O) and finite verb (V), there are six logical possibilities for their order: SOV, SVO, OSV, OVS, VSO,VOS. If the choice were completely random, we would expect that each pattern were found equally often in the languages of the world, but this is not the case. Instead, the two patterns that start with the subject are by far more frequent than the rest. Here is the result of an investigation of 1377 languages (Dryer 2013a; consult this source for more information and example sentences):
| Basic order | Example | Number of languages |
| SOV | Turkish, Saliba | 565 |
| SVO | French, Lelemi | 488 |
| VSO | Welsh, Maori | 95 |
| VOS | Malagasy, Tsotsil | 25 |
| OVS | Hixkaryana | 11 |
| OSV | Nadëb | 4 |
| no dominant order | Hungarian, Nunggubuyu | 189 |
| total | 1377 |
From these data we may infer that there is a strong preference to put the subject before the object – only in 40 of the 1377 investigated languages the object precedes the subject in basic word order (in the patterns VOS, OVS and OSV). Note that in this investigation only nominal subjects and objects were considered (like in The cat chased the bird), not those expressed by a pronoun (like in He chased it) or a person marker on the finite verb.
Polar questions
Another function of word order in German is to distinguish declarative sentences from interrogative sentences, or more precisely sentences that express polar questions (those that can be answered by “yes” or “no”). While in declarative sentences the verb is at the second position, in polar questions it is put at the first place, usually followed by the subject: Liebt er mich? ‘Does he love me?’, Liebt er mich vielleicht? ‘Does he love me, maybe?’, Liebt er vielleicht mich? ‘Is it maybe me he loves?’. This technique of marking questions is found mainly in European languages (German, Dutch, Swedish, Czech, Spanish and others), only occasionally in other parts of the world. The different techniques used in polar questions and their occurrence in the languages of the world are described in WALS, Chapter 116 (Dryer 2013b).
The most popular technique for marking questions in the languages of the world is by a question particle, as Polish czy. In Polish and many other languages the question particle is placed at the beginning of the sentence, while in other languages it is placed at the end, or after the first word of the clause.
| Language | Example | |
| Polish | Jan kupił książki.
Czy Jan kupił książki? |
‘Jan bought books.’ ‘Did Jan buy books?’ |
| Maybrat | ana m-amao Kumurkek a 3pl 3-go Kumurkek q |
‘Are they going to Kumurkek?’ |
| Mono | Charley =w̃aʔ mia-pɨ Charley = q go-perf |
‘Has Charley left?’ (the question marker is a clitic that attaches to the first word) |
Some languages mark questions in the verb-form. In this case, it is more common to have a special inflectional form used in questions, while the verb-form of declarative sentences is unmarked. However, in a few languages the opposite constellation is found: declarative sentences contain an obligatory marker (for example, for mood) which interrogative sentences lack. The following examples are from two languages spoken in Ethiopia:
| Language | Example | |
| Zayse | hamá-tte-ten háma-ten |
‘I will go’ ‘Will I go?’ |
| Sheko | ṇ-māāk-ā-m ṇ-māāk-ā únà ʂókú tuurùk’à tʂ’ádǹ kìákɘ únà ʂókú tuurùk’à tʂ’ádǹ kìa |
‘I will tell’ ‘Shall I tell?’‘In the past, there has been war in Sheko.’ ‘In the past, has there been war in Sheko?’ |
In most languages questions have an intonation different from declarative sentences, and often this is the only feature that distinguishes interrogative sentences from declarative sentences.
Go to the Interactive Map and try exercises on ǂAkhoe, exercise 1
How to express possession
There are several ways to express the same content, even in one language. A good example to show this is possession, that is the meaning ‘someone has something’, ‘something belongs to someone’. For example, in English we can say She has red hair, or Her hair is red, She is red-haired, She is a redhead… The possibilities vary with the things possessed. We cannot say * She is red-cared for ‘she has a red car’, and we don’t say * She owns red hair, while She owns a red car is fine. In most languages of western Europe (including Polish) the construction with a verb meaning ‘have’ is the most basic; it is used with very different kinds of “possession” (compare: I have a car / I have a brother / I have time / I have a headache …).
| Terminology | |
| possession | the relation between a possessor and a possessum, meaning ‘have’, ‘own’, ‘belong’ |
| possessor | the “owner” in a broad sense: someone or something that has something; in the English sentences John has red hair, John owns two houses, This car belongs to John, and in the phrase John’s father the name John expresses the possessor |
| possessum | what belongs to someone or something; in the sentences Suzie has a car, This car belong belongs to Mary, My mother’s car is red, the possessum is (a/this) car |
In Greenlandic, the verb ‘have’ and the noun expressing the thing possessed are combined in a compound verb:
| Language | example | |
| Greenlandic | angut taanna qimmi-qar-puq man that dog-have-3sg.ind |
‘That man has dogs’, literally: “That man dog-owns” |
In constructions of the ‘have’-type the possessor is encoded as the subject of the clause. Many languages of the world prefer other constructions. In a sample of 240 languages, only 63 had an equivalent of English have, and many of these are spoken in western or central Europe (Stassen 2013, chapter 117 of WALS). Languages that don’t have a verb meaning ‘have’ usually use a construction with a verb meaning ‘be’. This is therefore called the ‘be’-type. It is more widespread in the languages of the world than the ‘have’-type. Here, it is the possessum that is encoded as the subject, and the verb expresses existence or location. The possessor is expressed in various ways, for example in a dative form, as in Hungarian and Sheko, or marked by a preposition, as in Irish. In other languages the meaning ‘I have a car’ is expressed in a construction that can be translated literally as “a car is with me”, or “my car exists”, or “speaking of me, there is a car”, etc.
| Language | Example | |
| Hungarian | Istvan-ak új autója van. Istvan-dat new car.poss is |
‘Istvan has a new car’ (Literally: ‘To Istvan is his new car.’) |
| Sheko | dādū t’āāgǹ íʃ-kǹ kìákɘ child two she-dat exists |
‘She has two children.’ (Literally: ‘There’s two children to her.’) |
| Irish | Tá cat beag agam. is cat small at.me Níl madra agam. is.not dog at.me |
‘I have a small cat.’‘I don’t have a dog’ |
| Avar | dir mašina bugo 1sg.gen car iii-be.pres |
‘I have a car’ (Literally: ‘My car is’) |
| Tondano | si tuama sie wewean anim.sg man top exist wale rua house two |
‘The man has two houses’ (Literally: ‘As far as the man is concerned, there are two houses’ |
Possession is expressed not only in clauses, but also in phrases like my car, John’s house, the father of my friend. As you can see in these examples, English uses several techniques in such phrases: a different word-form (I – my, he – his, we – our), a clitic attached to the last word of a noun phrase (John – John’s, [the new teacher] – [the new teacher]’s), or a preposition ([my friend] – of [my friend]). In all these cases the relation “possession” is marked at the word or phrase that denotes the possessor, while the possessum is expressed in the basic form (see table 1).
In Hungarian we also find several construction types, but in contrast to English, it is the possessum that always bears the mark of the relation while the possessor may be unmarked, for example: István könyv-e ‘István’s book’, a diák könyv-e ‘the student’s book’ (see table 2). Recall the example ‘declaration of human rights’ from the beginning of this chapter: in Hungarian the relation between ‘human rights’ and ‘declaration’ is marked by the suffix -a at the word nyilatkozat ‘declaration’.
emberi jogok nyilatkozat-a
human rights declaration-POSS
In the case of first and second person, the possessor is expressed in Hungarian as a suffix on the noun denoting the possessum, for example könyv-em ‘my book’, könyv-ed ‘your book’.
In another Hungarian construction both the possessor and the possessum are marked: István-ak könyv-e ‘István’s book’, a diák-ak a könyv-e (see table 3).
| possessor | possessum | ||
| basic form | as possessor | basic form | as possessed |
| I | my | car | = |
| he | his | house | = |
| John | John’s | book | = |
| my friend | of my friend | the father | = |
| human rights | of human rights | declaration | = |
| possessor | possessum | ||
| basic form | as possessor | basic form | as possessed |
| István | = | könyv ‘book’ | könyv-e |
| diák ‘student’ | = | ||
| emberi jogok ‘human rights’ | = | nyilatkozat ‘declaration’ | nyilatkozat-a |
| én ‘I’ | -(e)m | könyv | könyv-em |
| te ‘you (sg.)’ | -(e)d | könyv-ed | |
| possessor | possessum | ||
| basic form | as possessor | basic form | as possessed |
| Istvánadiák ‘the student’ | István-aka diak-ak | a könyv ‘the book’ | a könyv-e |
Further examples for the three strategies:
| Language | Example | Strategy: marking of… |
| Chechen | mashie-an maax car-gen price‘The price of a car’ |
possessor |
| Yurakaré | shunñe a-pojore man 3sg.p-canoe‘the man’s canoe’ti-bba ‘my husband’ 1sg-husband |
possessum |
| Southern Sierra Miwok | cuku-ƞ hu:kiʔ-hy dog-gen tail-3sg‘the dog’s tail’ |
possessor and possessum |
| Puma | uƞ-bo uƞ-khim 1sg-gen 1sg-house‘my house’ kenci-bo kenci-khim 2dua-gen 2dua-house ‘your house’ (“the house of you two”) khokkuci-bo kʌci-khim ‘their house’ |
possessor and possessum |
| Asmat | Warsé ci ‘Warsé’s canoe’ Warsé canoe no cem ‘my house’ I house |
neither possessor nor possessum (rare) |
Many languages use different constructions for different kinds of “possession”. For example, one construction is used for kinship (‘my sister’, ‘my father’) or body parts (‘my hair’, ‘my nose’) and another construction for things that can be owned and sold (‘my house’, ‘my book’). The first type is called inalienable possession, the second type alienable possession. The following examples are from Saliba, an Austronesian language spoken in Papua New Guinea (Mosel 1994):
| sinagu | my mother | inalienable possession |
| sinana | his/her mother | |
| tamana | his/her father | |
| nimana | his/her hand | |
| Maui nimana |
Maui’s hand |
|
| yogu numa | my house | alienable possession |
| yona numa | his/her house | |
| Maui yona numa | Maui’s house |
Go to the Interactive Map an try Daakaka exercises on possession.
How to show the structure of words and clauses
In this chapter, examples from various languages were presented using a technique that is called “interlinear translation” or “morpheme-by-morpheme glossing”; linguists often simply call it “glossing”. This technique helps to understand the structure of examples from languages that we don’t know. For example, talking about questions in section 4 above, a sentence from the West Papuan language Maybrat was shown in this way:
| ana | m-amao | Kumurkek | a |
| 3PL | 3-go | Kumurkek | Q |
The glosses in the second line tell us that the first word is a pronoun for third person plural, the second word starts with a prefix that marks third person, followed by a root meaning ‘go’, the third word is a proper noun, and the last word is a question particle. With this information, we can construct the meaning of the whole sentence. Note that it is not possible to translate each word of the Maybrat example by an English word – there is no question particle in English, nor is there a marker for third person (the marker – s in talk-s, smile-s etc. is more specific, it marks third person singular). Glossing is largely independent of the grammatical structure of the language into which we translate. Only lexical roots are translated into this language, but all grammatical information that a word contains is indicated by a grammatical label such as pl for plural, 3 for third person. Grammatical must of course be explained (commonly by giving a list of abbreviations, as below).
The words of the language you want to describe (the object language) are segmented into components (morphs), separated by hyphens, for example:
The boy scream-ed and ran quick-ly to his mother.
Then the meaning of each component is written exactly below the segment. The number of hyphens has to be the same in both lines. If a segment includes more than one meaning, the glosses of this segment are separated by a period in the translation. The lexical roots are translated by words of the language of the description (the meta-language). Grammatical morphemes, including function words, are translated by grammatical labels; function words may also be translated by a corresponding function word, if there is one. A morpheme-by-morpheme glossing of the above sentence into Polish may thus look like this (note: the function words and and to could also be translated by a Polish equivalent, i and do, respectively):
| The | boy | scream-ed | and | ran | quick-ly | to | his | mother. |
| ART | chłopak | krzyczeć-PST | CONJ | biegać.PST | szybko-ADV | PREP | 3SG.M.POSS | matka |
Glossing is a very effective tool for linguistic description, especially if we want to compare the structures of very different languages. Reading glosses is not difficult, it just needs some training. Here are morpheme-by-morpheme glosses of the examples from the beginning of this chapter – the phrase “universal declaration of human rights” in four European languages:
Estonian
| Inim-oigus-te | üld-deklaratsioon |
| man-right-GEN.PL | general-declaration |
German
| allgemein-e | Erklär-ung | der | Mensch-en-recht-e |
| general-PL | declare-NOUN | ART.GEN.PL | man-AFX-right-PL |
Polish
| powszechn-a | deklaracj-a | praw | człowiek-a |
| general-NOM.SG.F | declaration-NOM.SG | right.GEN.PL | man-GEN.SG |
Hungarian
| az | ember-i | jog-ok | egyetemes | nyilatkozat-a |
| ART | man-ADJ | right-PL | general | declaration-POSS |
For details on glossing you may consult the “Leipzig Glossing Rules”, a standard way of glossing used by many linguists.
Go to the Interactive Map, find Teop and try reading glosses in exercise 3 (Part B). You can download the exercise here.
Exercise
Try to make an interlinear translation of a short text fragment (1 paragraph) in your mother tongue, using English as a metalanguage!
Abbreviations used in the glosses in this chapter
| ADJ | adjective (affix for building adjectives) |
| AFX | affix (unspecified) |
| ANIM | animate |
| ART | article |
| CLF | classifier |
| COND | conditional |
| CONJ | conjunction |
| DAT | dative |
| DUA | dual |
| F | feminine |
| GEN | genitive |
| IMPF | imperfective (aspect) |
| IND | indicative (mood) |
| NOM | nominative |
| NOUN | affix for building nouns |
| PERF | perfect |
| PL | plural |
| POSS | possession |
| PREP | preposition |
| PRES | present tense |
| PST | past |
| Q | question particle or affix |
| SG | singular |
| TAM | marker of tense, aspect and/or mood |
| TNS | tense |
| TOP | topic (what is talked about) |
Let’s Revise! – Chapter 3
Go to the Let’s Revise section to see what you can learn from this chapter or test how much you have already learnt!
Notes
[1] The text of the Universal Declaration of Human Rights in various languages can be found at http://www.ohchr.org/EN/UDHR/Pages/Introduction.aspx
Further reading
On different language structures
- Dryer, Matthew & Haspelmath, Martin (eds.). 2013. The World Atlas of Language Structures Online. Munich: Max Planck Digital Library. Available online at http://wals.info/
- Dürr, Michael & Schlobinski, Peter. 2006. Deskriptive Linguistik: Grundlagen und Methoden. Göttingen: Vandenhoeck und Ruprecht. [Third edition; earlier editions had the title „Einführung in die deskriptive Linguistik“]
- Haspelmath, Martin & Sims, Andrea. 2010. Understanding morphology. 2nd edition. London: Hodder Education.
- Payne, Thomas E. 1997. Describing morphosyntax. A guide for field linguists. Cambridge: Cambridge University Press.
- Payne, Thomas E. 2006. Exploring language structure: A student’s guide. New York: Cambridge University Press.
References
Sources of the language data
Amele: Graz Database on Reduplication, citing Roberts 1991; Asmat: Nichols & Bickel 2013, citing Voorhoeve 1965; Avar: Stassen 2013, citing Kalinina 1993; Chamorro: Cysouw 2013a, citing Topping 1973; Chechen: Nichols & Bickel 2013; Cherokee: Seifart 2010, citing Blankenship 1997; Choctaw: Rubino 2013, citing Kimball 1988; Greenlandic: Stassen 2013, citing Fortescue 1984; Irish: Data provided by Mike Hornsby; Lakhota: Albright 2000; Logba: Dorvlo 2008; Maybrat: Dryer 2013b, citing Dol 1999; Minangkabau: Gil 2013; Mlabri: Rischel 1999; Mono: Dryer 2013c, citing Norris 1986; Puma: Sharma et al. (online); Saliba: Mosel 1994; Sheko: Hellenthal 2010; Southern Sierra Miwok: Nichols & Bickel 2013, citing Broadbent 1964; Teop: Mosel 2007; Tondano: Stassen 2013, citing Sneddon 1975; Yimas: Seifart 2010, citing Foley 1991; Yurakaré: Van Gijn 2006; Zayse: Dryer 2013b, citing Hayward 1990.
- Albright, Adam. 2000. The productivity of infixation in Lakhota. Unpublished paper prepared for publication in UCLA Working Papers in Linguistics. Available online.
- Bauer, Laurie. 1988. Introducing linguistic morphology. Edinburgh: Edinburgh University Press.
- Blankenship, Barbara. 1997. Classificatory verbs in Cherokee. Anthropological Linguistics 39, 92-110.
- Broadbent, Sylvia M. 1964. The Southern Sierra Miwok language. University of Chicago Press.
- Corbett, Greville G. 2004. Number. Cambridge: Cambridge University Press.
- Corbett, Greville G. 2013. Number of genders. In: Dryer, Matthew & Haspelmath, Martin (eds.), The World Atlas of Language Structures Online. Munich: Max Planck Digital Library, Chapter 30.
- Cysouw, Michael. 2013a. Inclusive/exclusive distinction in independent pronouns. In: Dryer, Matthew & Haspelmath, Martin (eds.), The World Atlas of Language Structures Online. Munich: Max Planck Digital Library, Chapter 39.
- Cysouw, Michael. 2013b. Inclusive/exclusive distinction in verbal inflection. In: Dryer, Matthew & Haspelmath, Martin (eds.), The World Atlas of Language Structures Online. Munich: Max Planck Digital Library, Chapter 40.
- Dixon, Robert M. W. 1980. The languages of Australia. Cambridge: Cambridge University Press.
- Dol, Philomena. 1999. A grammar of Maybrat: A language of the Bird’s Head, Irian Jaya, Indonesia. University of Leiden.
- Dorvlo, Kofi. 2008. A grammar of Logba (Ikpana). Proefschrift, Universiteit Leiden. Available online.
- Dryer, Matthew S. 2013a. Order of subject, object and verb. In: Dryer, Matthew & Haspelmath, Martin (eds.), The World Atlas of Language Structures Online. Munich: Max Planck Digital Library, Chapter 81. /li>
- Dryer, Matthew S. 2013b. Polar questions. In: Dryer, Matthew & Haspelmath, Martin (eds.), The World Atlas of Language Structures Online. Munich: Max Planck Digital Library, Chapter 116.
- Dryer, Matthew S. 2013c. Position of polar question particles. In: Dryer, Matthew & Haspelmath, Martin (eds.), The World Atlas of Language Structures Online. Munich: Max Planck Digital Library, Chapter 92.
- Foley, William A. 1991. The Yimas language of New Guinea. Stanford: Stanford University Press.
- Fortescue, Michael. 1984. West Greenlandic. Croom Helm.
- Hayward, Richard J. 1990. Notes on the Zayse Language. School of Oriental and African Studies, University of London.
- Gil, David. 2013. Numeral classifiers. In: Dryer, Matthew & Haspelmath, Martin (eds.), The World Atlas of Language Structures Online. Munich: Max Planck Digital Library, Chapter 55.
- Graz Database on Reduplication at http://reduplication.uni-graz.at/redup/ [30.05.2012]
- Hellenthal, Anneke Christine. 2010. A grammar of Sheko. Proefschrift, Universiteit Leiden. Available online.
- Kalinina, E. 1993. Sentences with non-verbal predicates in the Sogratl dialect of Avar. In: A. E. Kibrik, ed. The noun phrase in the Andalal dialect of Avara as spoken at Sogratl, 90-104. Eurotyp Working Papers.
- Kimball, Geoffrey D. 1988. Koasati reduplication. In: W. Shiplay, ed. In honor of Mary Haas, 431-442. Mouton de Gruyter.
- Mosel, Ulrike. 1994. Saliba. München: LINCOM.
- Mosel, Ulrike, with Yvonne Thiesen. 2007. The Teop sketch grammar. Version 2007. Online publication available at the DOBES archive.
- Nichols, Johanna & Bickel, Balthasar. 2013. Locus of marking in possessive noun phrases. In: Dryer, Matthew & Haspelmath, Martin (eds.), The World Atlas of Language Structures Online. Munich: Max Planck Digital Library, Chapter 24.
- Norris, Evan J. 1986. A grammar sketch and comparative study of Eastern Mono. University of California at San Diego.
- Rischel, Jørgen. 1995. Minor Mlabri. A hunter-gatherer language of Northern Indochina. Copenhagen: Museum Tusculanum Press.
- Roberts, John R. 1987. Amele. Croom Helm.
- Roberts, John R. 1991. Reduplication in Amele. In: T. Dutton, ed. Papers in Papuan linguistics, No. 1, 115-146. Pacific Linguistics, A-73, 1991.
- Rubino, Carl. 2013. Reduplication. In: Dryer, Matthew & Haspelmath, Martin (eds.), The World Atlas of Language Structures Online. Munich: Max Planck Digital Library, Chapter 27.
- Sharma, Narayan P., Balthasar Bickel, Martin Gaenszle, Arjun Rai, and Vishnu S. Rai. Personal and possessive pronouns in Puma (Southern Kiranti). Online publication.
- Seifart, Frank. 2010. Nominal Classification. Language and Linguistics Compass 4/8 (2010): 719-736.
- Sneddon, James N. 1975. Tondano phonology and grammar. Australian National University.
- Stassen, Leo. 2013. Predicative possession. In: Dryer, Matthew & Haspelmath, Martin (eds.), The World Atlas of Language Structures Online. Munich: Max Planck Digital Library, Chapter 117.
- Universal Declaration of Human Rights in various languages: http://www.ohchr.org/EN/UDHR/Pages/Introduction.aspx [15.05.2012]
- Van Gijn, Erik. 2006. A grammar of Yurakaré. Proefschrift (PhD thesis), Radboud Universiteit Nijmegen. Available online.
- Voorhoeve, Clemens L. 1965. The Flamingo Bay dialect of the Asmat language. University of Leiden.